

读写模式问题
- 按字节处理:对每个字节进行循环,处理

- 按行处理:逐行处理,尤其是excel数据。.redline():读入一行

- 读取所有内容进行处理:把IO的次数降到最低。读取一次,提高效率。局限:文件过大的话内存会不够用,效率反而降低。

- 使用fileinput实行行迭代

- 使用文件迭代器进行迭代:

读写模式问题
文件对象的基本方法
读和写

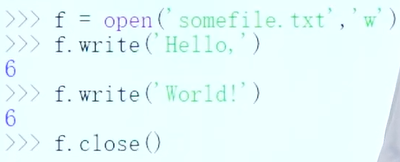
文件打开

函数的作用域



函数的参数

把n当作列表,操作针对列表,n储存的是列表的储存地址。改变时就能改变列表的内容。
参数的类型


关键字参数:位置不敏感。(调用方式:调用时告知关键字,以关键字匹配)参数名和值一点更要对应。
定义关键字参数:为参数提供默认值。可以用位置参数调用,也可以用关键字参数调用。

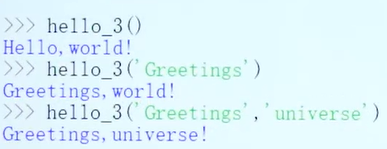

位置参数和关键字参数混用。位置参数在前面,关键字在后面。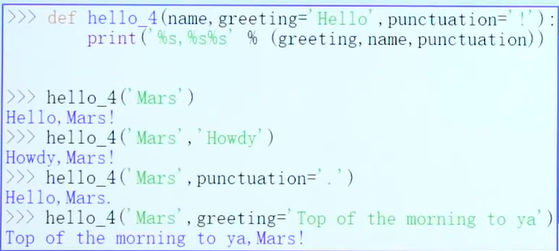
参数收集




输入任意多个关键字参数:带**号:收集其余的关键字参数(变为字典)
执行相反的操作:在调用阶段使用*或**:将元组或字典拆成位置参数或关键字参数。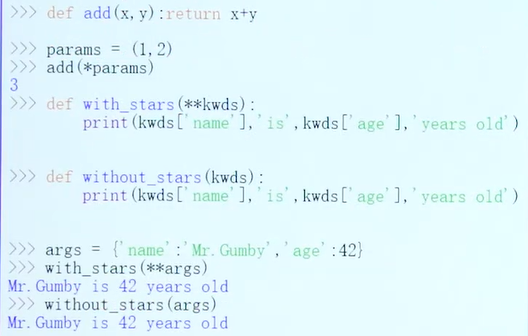
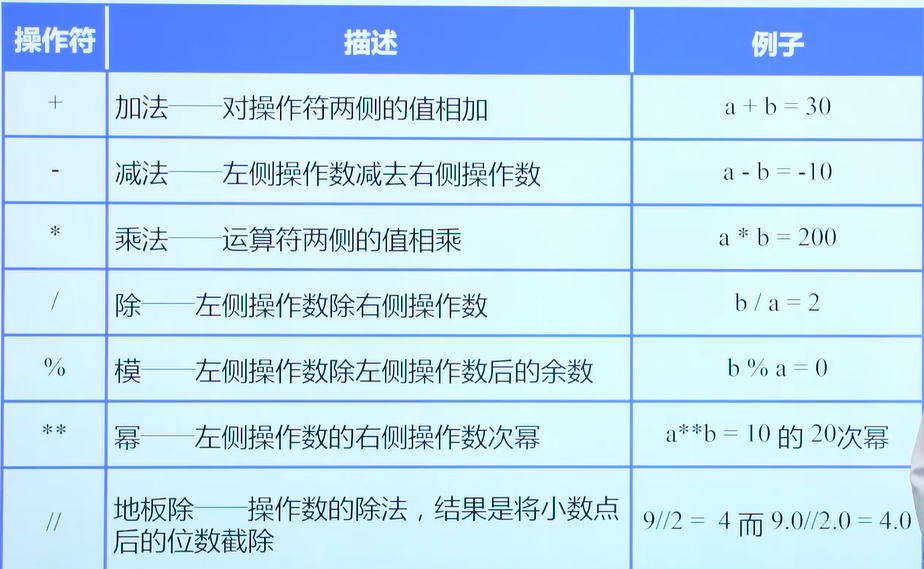
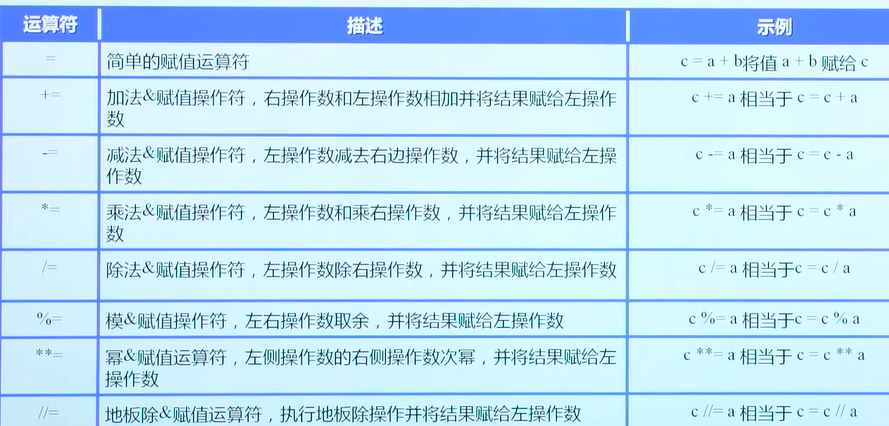
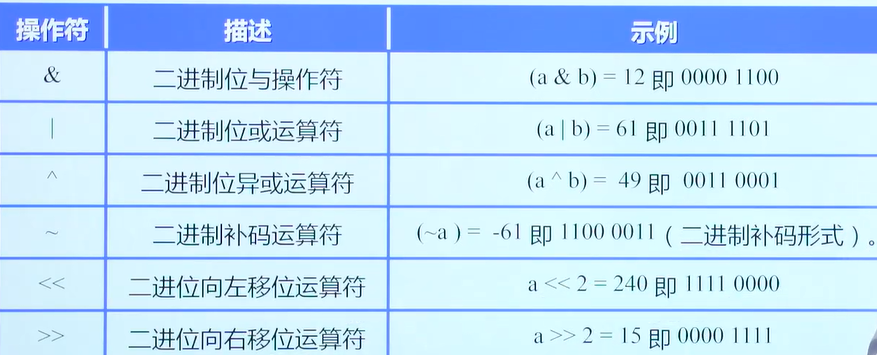
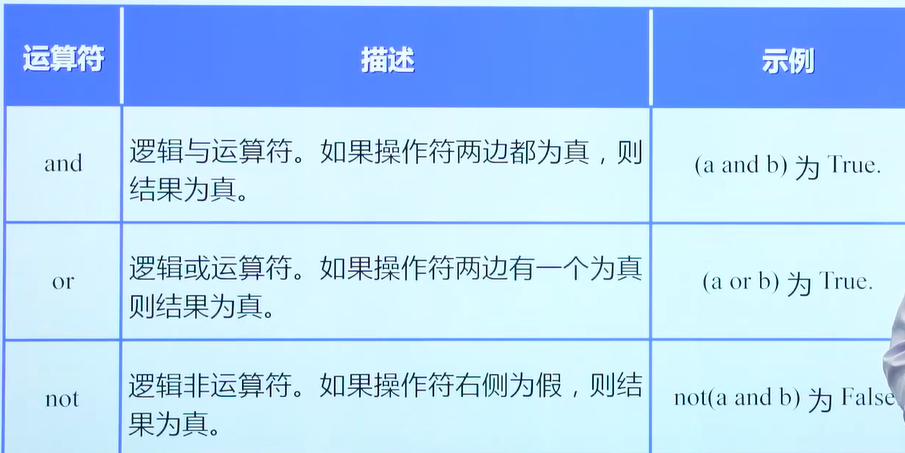
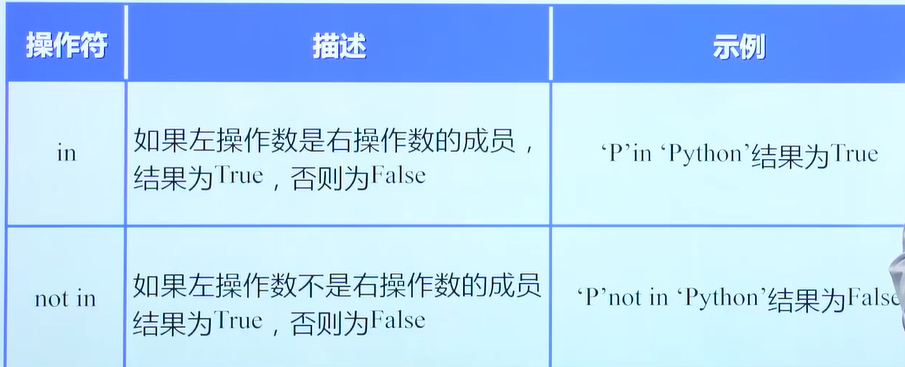
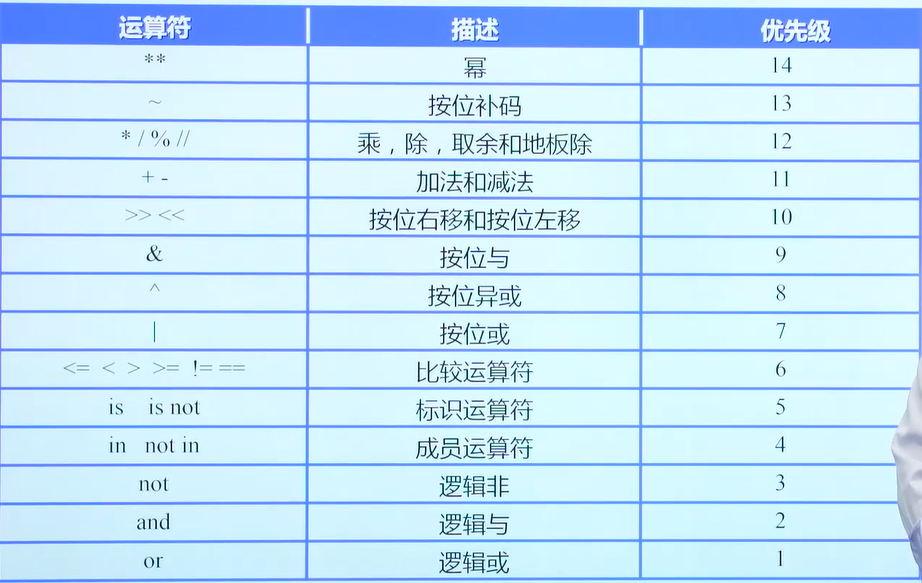
基本运算符



集合(set)
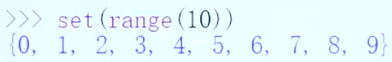



集合是可变的,集合中的元素不可变——集合不能套集合(.add):添加元素
frozenset:不可变的集合
集合的其他操作

文件与流
打开文件




缓冲
编码
函数


创建函数





记录函数



返回None的函数
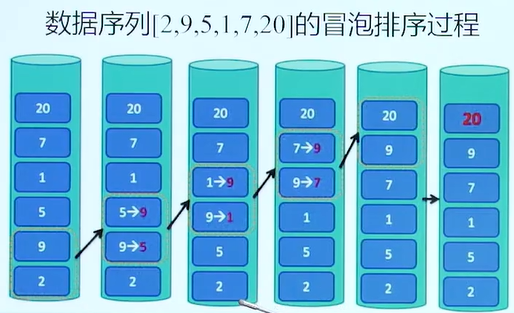
排序算法
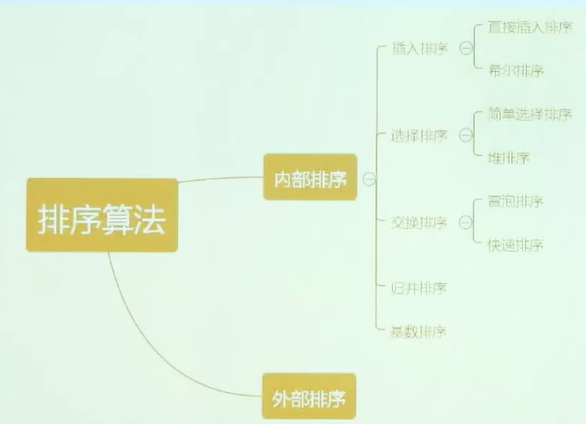
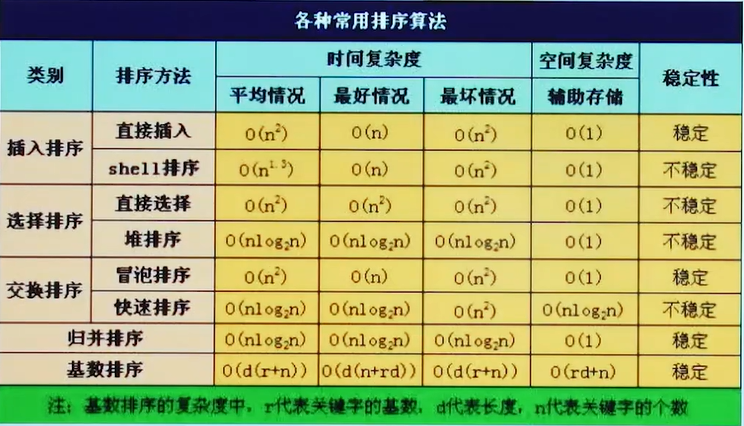
冒泡排序
函数
并行迭代:多个序列同时迭代


编号迭代


汉诺塔问题
递归函数




原理图示:
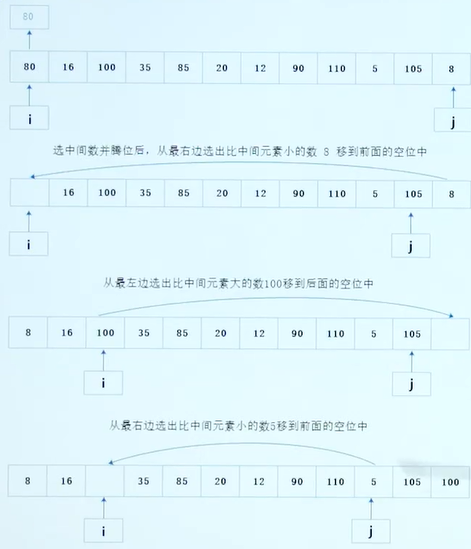
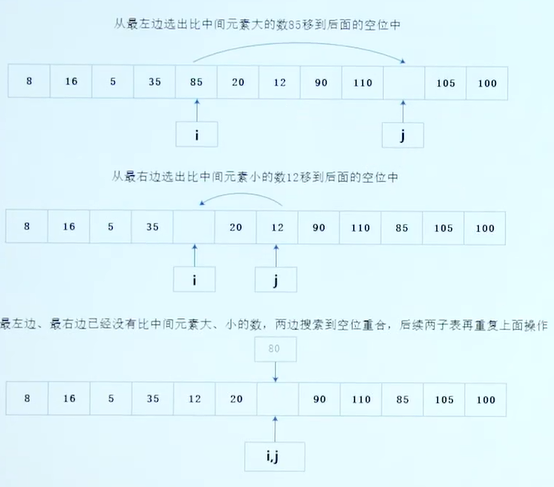 快速排序的递归写法:
快速排序的递归写法:
列表

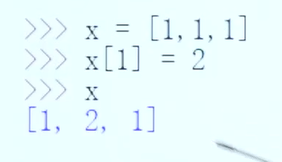









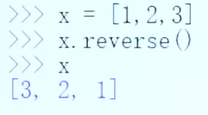





有返回值VS无返回值
“.”的意思:列表的独有方法
“[]”与“()”的区别:[]表示列表或者列表变量,其他都要用()
跳出循环



轻量级循环: 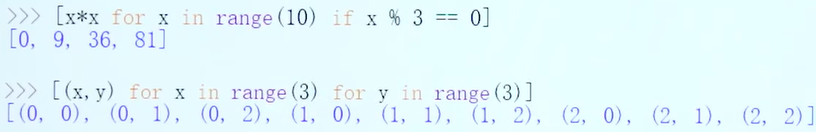

循环


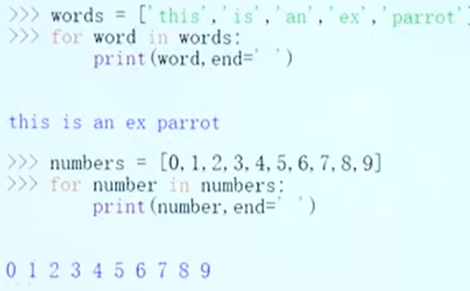


条件与循环
语句块

布尔变量
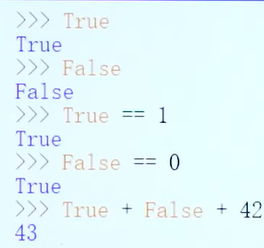

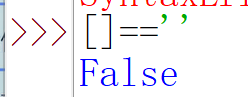
条件和条件语句




断言

字符串和编码
字符编码:
字符串:用绿色高亮,用‘’或“”圈出来。

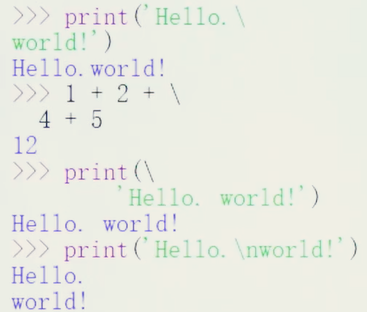



字符串的基本操作
序列:操作一组数值是,表示一串数字、一列数字,用[ ]表示。元素用,隔开,可以不是一种类型。
e.g. edward=['hello',42,6,'你好']
序列中也可以包含其他序列
序列通用操作





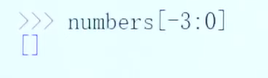


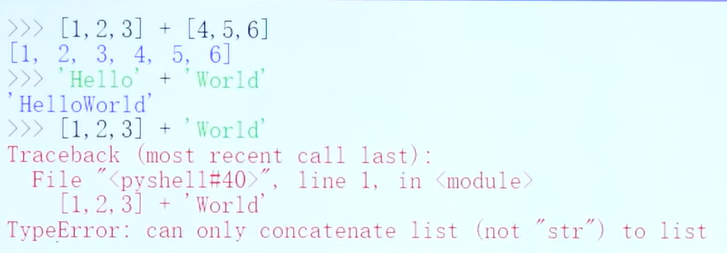

![]()
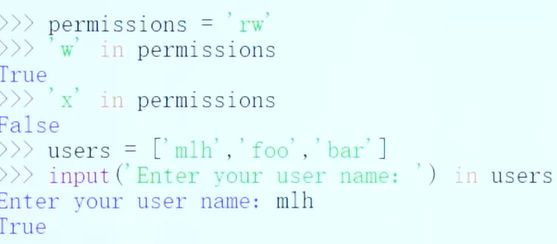

基本运算符
算数运算符
1、from key
用给定的键创建心的字典
每个键默认对应的值为None,也可以改变默认值
2、get
用键来取
3、item
张瑾,中国人民大学商学院副院长,教授,博士生导师。分别于2013年、2009年、2006年获清华大学管理学博士、工学硕士和工学学士学位。获教育部高等学校科学研究优秀成果奖、教育部博士研究生学术新人奖、北京市哲学社会科学优秀成果二等奖、北京市优秀学位论文优秀指导教师、北京市优秀博士毕业生、中国信息经济学会理论贡献奖,中国人民大学教学优秀奖,清华大学优秀博士论文奖等荣誉。在国内外重要学术期刊与会议上发表学术论文三十余篇,其中四篇为管理学国际顶级期刊(UTD 24)论文。主持三项国家自然科学基金项目,其中一项在基金委后评估中被评为“特优”,并带领团队在汽车、电信、传媒、核电、互联网等行业完成多个政府和企业课题。主要教学与研究领域包括人工智能与数字经济,大数据分析与管理,机器学习与商务智能等
