

常用方法
1、clear方法
是原地操作,原始结果改变了
2、copy方法
重新复制一份,拷贝的结果装到新的
但是,如果值对应的是特殊类型,比如列表,实际存储的是列表所在的地址,那么列表发生改变后,复制过去的列表的内容也会发生改变
deep copy
常用方法
1、clear方法
是原地操作,原始结果改变了
2、copy方法
重新复制一份,拷贝的结果装到新的
但是,如果值对应的是特殊类型,比如列表,实际存储的是列表所在的地址,那么列表发生改变后,复制过去的列表的内容也会发生改变
deep copy
字典
没有顺序(区别于序列)
映射类型,键值对
Key和Value
key是唯一的
value无所谓,可以是相同的值
没有对键值对进行排序
创建办法:
1、直接创建{ “A”:“B”, ,}
A 是 KEY,B是VALE
B可以重复
A不可以重复
2、dict函数创建
先创建一对
items=[('name',Gumby),('age',42)]
a=dict(item)
{“name”:“Gumby”……}
3、不用二元组,直接表示
d=dict(name=‘’Gumby‘’……)
字典的基本操作
1、len(b)算键值对的数量
2、取定向的值 用键来取
d[k]返回k键上的值
3、del d[k]删除键为k的项
4、k in d 检查d中是否含有键为K的项
5、字典可以改值 d[k]=v
字典的值可以改
字典的键不可以改
自动添加,若果键不在原来所建的范围里还是可以通过并且建立新的键
成员资格 :检查的是键是否在而不是值
列表检查的是值
6、键可以为任何不可变类型,可以自动创建新的键
X={}
X[42]='foobar'
7、字符格式化字串
更新字典
4.5 字符串的常用方法
(1)find:在一个较长的字符串中查找子字符串,它返回子串所在位置的最左端索引。如果没有找到则返回-1。
e.g. title="Monty Pytho's Flying Circus"
title.find('Monty')
得到0
subject.find('$$$ Get rich now!!! $$$')
subject.find('!!!',0,16) #提供起始点和结束点
得到-1
(2)join:在队列中添加元素,添加的队列元素都必须是字符串
e.g. q=['1','2','3','4','5']
p.join(q)
得到'1+2+3+4+5'
(3)strip:返回去除两侧(不包括内部)包含参数的字符串(常用于“清洗”数据)
参数为空时,默认删除空白符。
e.g. ' internal white space is kept '.strip()
得到'internal white space is kept'
(4)lower:返回字符串的小写字母版。
(5)replace:返回某字符串的所有匹配项均被替换之后得到的字符串(不改变原值)
name.replace('被替换值','替换值')
(6)split:用来将字符串分割成序列,如果不提供任何分隔符,程序会把所有空格作为分隔符(空格、制表、换行等),它是join的逆方法。
e.g. '1+2+3+4+5'.split('+')
得到['1','2','3','4','5']
(7)translate:替换字符串中的某些部分,并且可以同时进行多个替换。
在使用translate转换之前,需要先完成一张转换表。该表直接在所有字符串类型str上调用maketrans函数。maketrans函数接受两个参数:两个等长的字符串,表示第一个字符串中的每个字符都用第二个字符串中相同位置的字符替换。如:
table=str.maketrans('cs','kz')
#c换成k,s换成z
test='hello computer science'
test.translate(table)
得到'hello komputer zkienke'
4.4字符串格式化
(1)在字符串输出时对其进行某种格式的控制。
(2)字符串格式化符:%百分号
%d:十进制表示 %X:十六进制表示
【例1】from math import pi
(其中math是一个module)
%i:整数表示 %f:浮点数表示
【例2】
format='Hello %s %s enough for ya'
values=('world','hot')
print(format % values)
得到Hello world hot enough for ya
可以一次性进行多个字符串格式化
(3)字符串格式化的转换类型(表格,书上有)
(4)关于格式化的宽度和精度
①可用*星号作为字符宽度或者精度,数值会从元组参数中读出。如:
'%10.2f' % pi #字符宽10,精度2
得到 3.14
'%*.*s' % (10,5,'Guido van Rossum')
得到 Guido
(宽度:字符串的长度,可能会用空格补位。精度:小数点保留的位数。)
字符串和编码
字符编码:把人熟悉的字符编码成字符串,本质上是一种映射。
使用字符编码声明:#coding:UTF-8
一个字节有8个比特位。
4.1长字符串
若要写一个很长的字符串,它需要跨多行,可以使用三个单引号“或双引号”代替普通引号。(单双引号不可混用)
4.1 原始字符串
①转义字符:反斜线\
e.g. \n: 换行 \+回车:空格
\\: 表示原本反斜线的含义
②原始字符串:在字符串前加上字母r。
注意:使用原始字符串时,末尾不可以有反斜线\,可以在原字符串后再添加一个新的表示反斜线的字符串。
标准的序列操作:索引、分片、乘法、判断成员资格、求长度、取最小值和最大值,除了改值的操作之外,对元组都适用。
元组与字符串
3.3 元组操作
1.元组:一种不可改值的序列。可以直接通过用逗号隔离一些值+回车创建(创建单值元组时单个原色后也需加逗号),用圆括号括起来。
2.空元组:用没有包含内容的两个圆括号表示
3.操作
(1)tuple函数:以一个序列作为参数并把它转换为元组。
4.意义
①元组可以在映射(和集合的成员)中当作键使用,而列表不行;
②元组不可修改!!!
字符串格式化
%d 十进制
%X 16进制、%?是占位
%f 以小数点形式
可以用多个占位
显示和控制支付的宽度和精度
宽度.精度
字符串要截断位置
元组和字符串
不可更改
圆弧括号
创建元组,直接用逗号隔开
空元组
只有一个值也要加逗号
元组操作
1.tuple函数
将序列变成元组
tuple([1,2,3])
(1,2,3)
索引、分片
x=1,2,3
x[0:2]
(1,2)
元组意义
防止修改
字符串常用方法
find函数用法
找到了 就返回字符串第一个字符处于的位置
没找到就返回-1
title.find(“”,起点,终点)
join方法
链接,在队列中添加元素“必须是字符串”
p.join(s)
strip(清洗)
清楚字符两段没用的空格
或者清除指定字符
‘’‘’.sripe()
''.stripe(*)
p.lower()
返回字符串小写字母
replace
'A is for B'.replace('is',"V")
'A V for B'
split,join的逆方法
"1+2+#+4+5".split('+')
[1,2,#,4,5]
translate替换定向的字母
先给转化表
table=str.maketrans('cs','kz')
test=''
test.translate(table)
字符串和编码
#coding:UTF-8
表示编码方式
长字符串,需要跨多行,用'''(或者双引号),代替普通引号,长字符串外面用单引号时,里面用双引号
绿色高亮内容
单引和双引成对使用
斜线:转义符
把斜线后的字符变成第二语义
\n:变成回车符号
\(换行):空格
r 表示声明原始字符串,长路径表示,不能在原始字符串结尾输入反斜线,除非用反斜线继续进行转义
不可以改值!!
>>>edward=['Edward Gumby',42]
>>>john=['John smith',50]
>>>database=[edward,john]
>>>database
[['Edward Gumby',42],['John smith',50]]
索引
>>>greeting='hello'
>>>greeting[0]
'h'
浮点数的存储不是准确的,整数是准确的
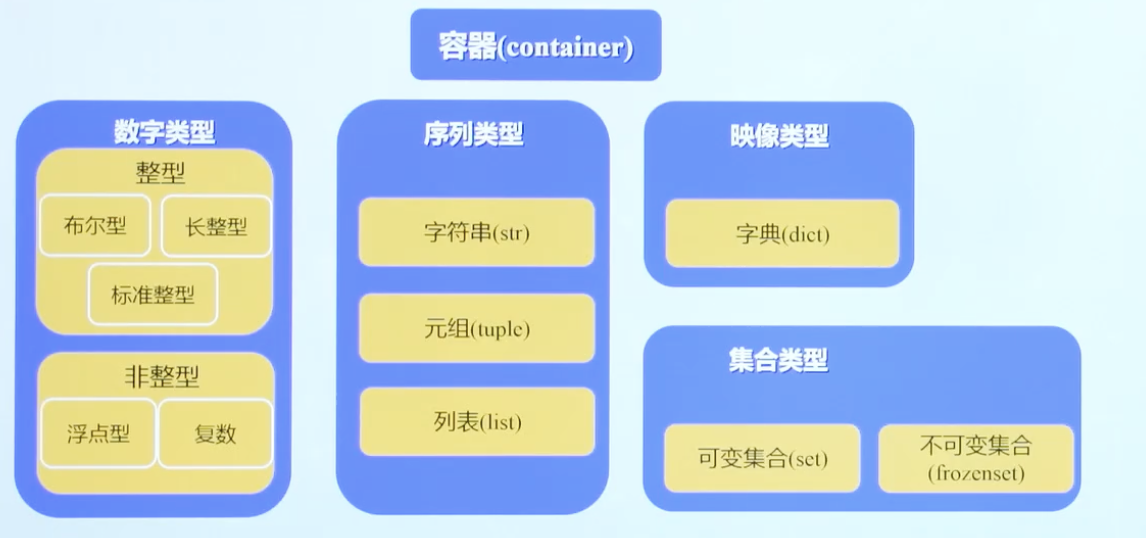
1.python基本数据类型(容器container)
(1)数字类型
-整型:布尔型、长整型(L)、标准整型(进制)
-非整型:浮点型(小数,e=10)、复数
【整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确地,而浮点数运算则可能会有四舍五入的误差】
>>>import cmath
>>>cmath.sqrt(-1)
1j
(2)序列类型:字符串(str)、元组(tuple)、列表(list)
(3)映像类型:字典(dict)
(4)集合类型:可变集合(set)、不可变集合(fro/enset )
dd
列表操作:
列表不同于元组和字符串,列表是可变的
1、改值
(内建函数)list函数:转换序列的三种类型,变成可以改值的列表,唯一一个可以被改值的操作。
2、元素赋值
利用索引定位,再赋值,然后改值
索引不能越界:不能为一个位置不存在的元素赋值
3、删除元素
del
4、分片赋值
先变成可以改值的列表
然后用索引定位
a=list('abcd')
a[:2]=list(234)
a
['2','3','4','d']
分片插入新元素
删除:del 或者 a[:2]=[ ]
5、append方法
. 很多方法
append:在列表末尾追加新的对象
a=[1,2,3]
a.append(4)
a
[1,2,3,4]
6、count方法
count:统计某个元素在列表中出现的次数
a.count()
7、extend
a=[1,2,3]
b=[4,5,6]
a.extend(b)
a
[1,2,3,4,5,6]
会改变a的值
a+b
[1,2,3,4,5,6]
a[1,2,3]
b[4,5,6]
a的值没有发生变化
8、index
找到某个值第一个匹配项的索引位置
a=[1,2,3]
a.index(1)
0
9、insert
将对象插入列表
a=[1,2,3]
a.insert(2,'3')
a
[1,2,3,3]
也可以分片赋值
10、reverse
将元素反向存放
x=[1,2,3]
x.reverse()
x
[3,2,1]
10、sort 排序
a=[1,23,4,3,21,43,55]
y=a.sort()
print(y)
None
sorted(不是原地操作)
原地操作 x值发生改变
对字母排序
sorted('a','c','f','e','m')
Traceback (most recent call last):
File "<pyshell#9>", line 1, in <module>
sorted('a','c','f','e','m')
TypeError: sorted expected 1 argument, got 5
sorted('acfem')
['a', 'c', 'e', 'f', 'm']
key:排序的依据
reverse:正序还是反序
x=[4,6,2,1,7,9]
x.sort(reverse=true)
x
[9,7,6,4,2,1]
序列
列表 元组 字符串
基本操作:
1、表达:(一维 )一行:[ ]
(二维)序列套序列:2x2矩阵
2、索引
定向取出某一块
位置索引,左侧从0开始记
右侧 从-1开始
变量名或者字符串直接索引都是可以的
对函数的返回结果直接索引
函数的执行结果?
3、分片
成片取出想要的数据
[a:b],a表示开始取的位子,b表示挺的位子,实际取到b-1
字符串
数字
python在分片操作时要确保起点在终点的左侧
(取不出来 结果为空)
终点和起点可以缺失,默认到头
两个冒号:a:b : c
a是起点 b是终点 c是步长
不写c就默认为+1
步长:步长为1就是一个个取,步长为2 就是隔一个取
负数步长:从右侧往左取(起点要在终点右侧)
4、相加
两个序列相加首先要类型相同
5、相乘
合在一起形成一个大的序列
None:既不是数字也不字符串 占位符
6、成员资格检查
in:查验某个条件是否为真
7、长度 最小值 最大值
紫色高亮:内建函数
函数
内建函数
算平方:pow(2,3) 2 ^3
round 取整:把浮点数四舍五入为最接近的整数值
round(1.0/2.0)
abs:取绝对值
模块
时间模块
import time
print(time.time())
年月日
time.localtime(time.time())
time.strftime('%Y-%m-%d',timr.localtime(time.time()))
输入
input()
输出
print()
赋值
多重赋值
a=b=c=1
a=b=c=1,2,3
第二章 第一讲
商业数据分析时代背景:企业数字化转型
企业数字化转型是什么
用IT刻画企业的管理过程,刻画管理者看到的管理师姐
思考差别:1、数字化 和信息化
信息化:用IT(信息系统)刻画静态的管理信息数据
数字化:IT成熟后刻画动态的管理过程(营销 客户管理)
2、智能化 和数字化
智能化:(消费者 员工 管理者)刻画清楚人的思考、决策过程
管理者寻求IT资源刻画管理过程
IT变化 管理世界变化
张瑾,中国人民大学商学院副院长,教授,博士生导师。分别于2013年、2009年、2006年获清华大学管理学博士、工学硕士和工学学士学位。获教育部高等学校科学研究优秀成果奖、教育部博士研究生学术新人奖、北京市哲学社会科学优秀成果二等奖、北京市优秀学位论文优秀指导教师、北京市优秀博士毕业生、中国信息经济学会理论贡献奖,中国人民大学教学优秀奖,清华大学优秀博士论文奖等荣誉。在国内外重要学术期刊与会议上发表学术论文三十余篇,其中四篇为管理学国际顶级期刊(UTD 24)论文。主持三项国家自然科学基金项目,其中一项在基金委后评估中被评为“特优”,并带领团队在汽车、电信、传媒、核电、互联网等行业完成多个政府和企业课题。主要教学与研究领域包括人工智能与数字经济,大数据分析与管理,机器学习与商务智能等
